B o o o k k k k k e e e e e h h h h h Diffusion
Defocus Blur Control in Text-to-Image Diffusion Models

Recent advances in large-scale text-to-image models have revolutionized creative fields by generating visually captivating outputs from textual prompts; however, while traditional photography offers precise control over camera settings to shape visual aesthetics---such as depth-of-field via aperture---current diffusion models typically rely on prompt engineering to mimic such effects. This approach often results in crude approximations and inadvertently alters the scene content.
In this work, we propose Bokeh Diffusion, a scene-consistent bokeh control framework that explicitly conditions a diffusion model on a physical defocus blur parameter. To overcome the scarcity of paired real-world images captured under different camera settings, we introduce a hybrid training pipeline that aligns in-the-wild images with synthetic blur augmentations, providing diverse scenes and subjects as well as supervision to learn the separation of image content from lens blur. Central to our framework is our grounded self-attention mechanism, trained on image pairs with different bokeh levels of the same scene, which enables blur strength to be adjusted in both directions while preserving the underlying scene.
Extensive experiments demonstrate that our approach enables flexible, lens-like blur control, supports downstream applications such as real image editing via inversion, and generalizes effectively across both Stable Diffusion and FLUX architectures.
Bokeh Diffusion combines three key components to produce lens-like bokeh without altering the generated scene content:
(1) Hybrid Dataset Pipeline: We merge real in-the-wild images with synthetic bokeh augmentations. This approach ensures realism and diversity while also providing contrastive examples for training.
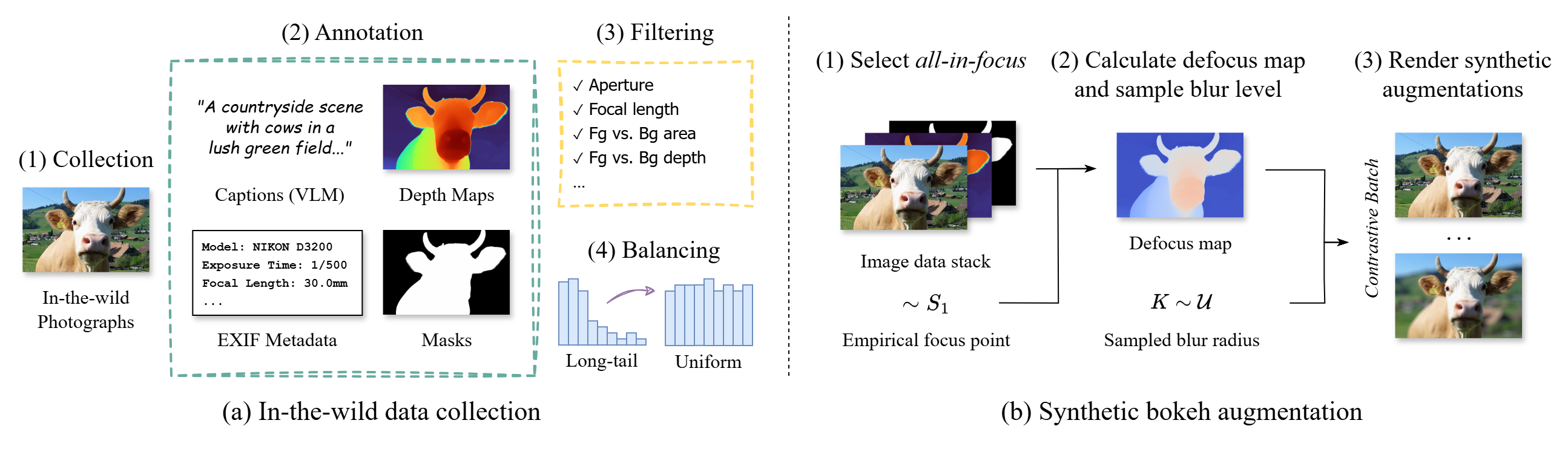
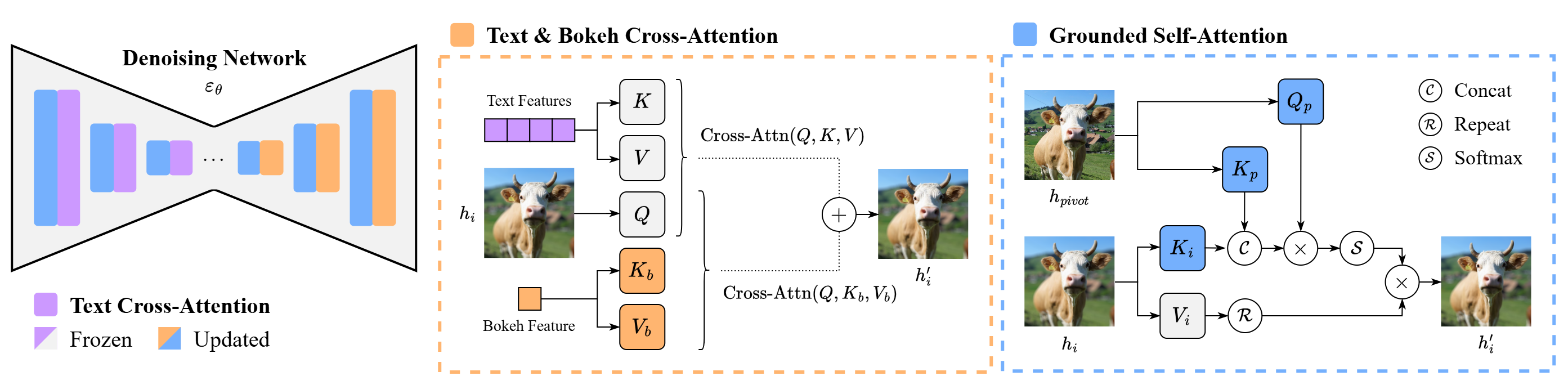
(2) Defocus Blur Conditioning: A physically interpretable defocus blur parameter is injected via decoupled cross-attention.
(3) Grounded Self-Attention: A pivot image anchors the generated scene, ensuring content preservation across bokeh levels.
A user can directly sample an image at the desired bokeh level.











Post-processing bokeh renderers often depend on external depth estimation tools.
Bokeh Diffusion leverages the generative prior of T2I diffusion models and our in-the-wild dataset to produce more natural bokeh in challenging areas (e.g., thin structures and translucent materials).